Im Zeitalter von “Big Data” und selbstlernenden Algorithmen scheinen Finanzbehörden einen Vorteil zu haben. Problem: Sie müssen erst Herr riesiger Datenberge werden.
Welche Algorithmen in den Computern der Finanzprüfer arbeiten, ist nicht nur in Deutschland ein sorgsam gehütetes Geheimnis. Auch ausländische Finanzministerien sind sehr darauf bedacht, potenziellen Steuerhinterziehern nicht allzu viele Einblicke zu geben.
So zitiert das Magazin U.S. News and World Report einen Topoffiziellen des Internal Revenue Service (IRS), der Bundessteuerbehörde der USA: “Die Privatindustrie wäre sehr neidisch, wenn sie wüsste, wie fortgeschritten unsere Modelle sind.” Doch darüber, auf welche Daten genau die Finanzbehörde zugreift und wie sie sie verarbeitet, gibt die Behörde kaum Stellungnahmen ab.
So wurde zwar durch Fachveröffentlichungen bekannt, dass die Behörde Techniken wie künstliche Intelligenz (KI) und maschinelles LernenMachine Learning Ein Teilbereich der KI, bei dem Systeme aus Daten lernen und sich verbessern, ohne explizit programmiert zu werden. einsetzt, auf Accounts in Sozialen Medien und sogar E-Mails von US-Bürgern zugreift – ob dies aber mehr Nischenanwendungen und Experimente sind, ist nicht öffentlich bekannt.
Die Forscherinnen Kimberly A. Houser und Debra Sanders kritisieren den zunehmenden Einsatz von Big-Data-Techniken in der US-Steuerverwaltung. Die Techniken seien eingeführt worden, um die Steuererhebung zu vergünstigen. So wurden im Jahr 2010 insgesamt 14 Prozent der Stellen beim Internal Revenue gestrichen, obwohl die Aufgaben der Behörde gleichzeitig erweitert wurden. Der geringeren Arbeitskraft wurde mit einer zunehmenden Automatisierung der Aufgaben begegnet, die wiederum zu einem immer höheren Datenhunger der Steuerverwaltung führte.
„Indem der IRS die Daten in nicht offener Form sammelt, werden Nutzer davon abgehalten, die Informationen über sie einzusehen oder gar zu korrigieren“, schreiben die Finanzwissenschaftlerinnen. Zudem setze die IRS prädiktive Techniken ein, um auf Informationen zu schließen, die der Behörde nicht vorliegen. „Wenn zum Beispiel ein Modell ermittelt, dass Leute mit einem Dackel ihre medizinischen Ausgaben zu hoch ansetzen, wäre es gerechtfertigt, jeden Dackelbesitzer einer Buchprüfung zu unterziehen?“ fragen die Autorinnen und ergänzen: „Stellen sie sich vor, die Gemeinsamkeit wäre kein Hund, sondern eine gemeinsame Ethnie oder Religion.“ Der Einsatz von Big-Data-Techniken könnte so zu einer Diskriminierung führen.
Auch Algorithmen haben blinde Flecken
Auch Linus Neumann, Sprecher des deutschen Hacker-Vereins Chaos Computer Club, warnt vor den Folgen der Einführung solcher Techniken. “Die durch selbstlernende Ansätze zustande kommenden Modelle sind oft nicht nur durch eine genauere Vorhersage, sondern häufig durch eine hohe Komplexität gekennzeichnet, die sie teilweise für Menschen nicht mehr in ihrer Gesamtheit verständlich nachvollziehbar macht. Die Folge sei: “Einzelne Entscheidungen können in ihrem Zustandekommen im Nachhinein nachvollzogen werden, jedoch nicht, wie die zugrunde liegenden Entscheidungskriterien überhaupt zustande gekommen sind.” Sprich: Die Algorithmen könnten einzelne Bevölkerungsgruppen diskriminieren, ohne dass dies beabsichtigt oder bemerkt wird.
Da die selbstlernenden Algorithmen nie besser sein können als die Trainingsdaten, von denen sie gelernt haben, sei deshalb eine konstante Überprüfung der Ergebnisse notwendig, um “blinde Flecken” zu vermeiden oder eine unangemessene Verfolgung Steuerpflichtiger zu verhindern, die rein zufällig in ein von den Algorithmen erfasstes Muster geraten. Zudem müssten Bürger das Recht haben, automatische Entscheidungen gegenprüfen zu lassen, fordert Neumann.
Big Data als Lösung?
Neben den fortgeschrittenen Techniken zur Auswertung der Daten nutzen die Behörden weltweit die inzwischen preisgünstigen Verarbeitungstechniken, um bisher ungenutzte Datenschätze zu nutzen. So werden bei italienischen Steuerbehörden bereits Techniken wie Maschinenlernen eingesetzt. Auch die deutsche Steuerverwaltung nutzt immer mehr Datenquellen, um ihre Aufgaben zu erfüllen.
Das reicht von relativ trivialen Anwendungen, um nicht deklarierte Einkünfte aufzuspüren. So wurde beispielsweise bereits 2003 bekannt, dass das Bundesamt für Finanzen routinemäßig mit der Suchsoftware XPIDER Onlinemarktplätze wie Ebay sucht, um professionelle Verkäufer aufzuspüren, die ihre Einnahmen nicht an das Finanzamt melden.
Doch solche Lösungen haben für sich genommen nur ein beschränktes Potenzial. So beklagte Bundesrechnungshof-Präsident Kay Scheller noch 2016, dass im Onlinehandel kaum verfolgt werde, ob ein Unternehmer die gesetzlich vorgeschriebene Mehrwertsteuer abführt. Eine Lösung dafür ist, immer neue Datenquellen heranzuziehen – von Social-Media-Accounts bis zu Internetforen.
Fehlende Anonymität in Zeiten von Social Media
Wie mächtig die Verbindung von verschiedenen Datenquellen sein kann, beweisen vier Wissenschaftler von der Universität Katar in einem Papier, das sie Anfang 2018 vorlegten. Sie kombinierten Daten aus Tweets, einem Bitcoinforum und dem anonymisierten Tornetzwerk. Ergebnis: Sie konnten über 125 Identitäten mit Organisationen wie Wikileaks, dem Untergrundmarktplatz Silk Road und der für Raubkopien bekannten Plattform The Piratebay verknüpfen und haarklein deren Transaktionen verfolgen. Die Forscher konnten den Accounts auch konkrete Identitäten zuweisen. “Bitcoinadressen sollten als kompromittiert gelten, weil man ihre Nutzer nachträglich enttarnen kann”, lautet die Schlussfolgerung der Forscher.
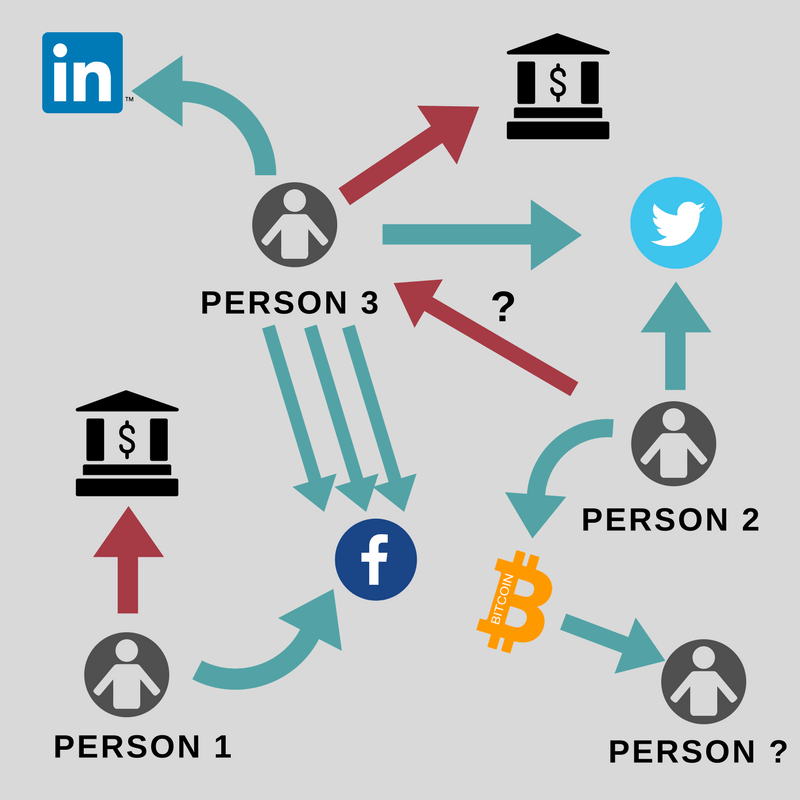
Behörden können Rückschlüsse auf Einkommen und Geschäftsbeziehungen der Steuerpflichtigen ziehen, indem sie öffentlichen Daten aus sozialen Netzwerken mit anderen Steuerdaten abgleichen. So gelang es Wissenschaftlern zum Beispiel mit Hilfe von Daten aus Internetforen Bitcoin-Nutzer zu identifizieren. (Grafik des Algorithmenethik Teams)
Möglich wurde dieses Ergebnis dadurch, dass Bitcoin trotz entgegenstehender Berichte nicht anonym, sondern pseudonym ist. Zwar sind den Bitcoinkonten, den sogenannten “Wallets”, per se keine Realnamen zugewiesen, sondern lediglich ein Nummerncode. Gleichzeitig werden jedoch alle Bitcointransaktionen für jeden sichtbar öffentlich gespeichert, sodass man nachträglich mit Analyseverfahren genau erkunden kann, welche Wallets zusammengehören und wer mit wem interagiert hat.
Kombiniert man dieses Wissen mit zusätzlichen Daten, ist eine Enttarnung der Nutzer kaum wirkungsvoll zu vermeiden. So konnten die Forscher alleine mit öffentlichen Social-Media-Accounts Identitäten entlarven, die womöglich Strafverfolgung zu befürchten haben. Staatliche Stellen haben freilich eine noch größere Datenbasis. Sie können über Geldwäschegesetze und die Analyse von Finanzdaten viel genauer verfolgen, woher Geldflüsse stammen und wem sie zugute gekommen sind. So ordnete schon im November 2017 ein US-Gericht an, dass die Bitcoinhandelsplattform Coinbase Daten von mehr als 14.000 Nutzern herausgeben musste, die pro Jahr mehr als 20.000 Dollar mit Kryptowährungen umsetzten.
Problem Verknüpfung: mangelnde Kompatibilität der Daten und fehlende Zusammenarbeit der EU Länder
Problem dabei: Auch wenn Daten digital vorliegen, bedeutet das noch lange nicht, dass man die Einkünfte auch einem Steuerpflichtigen zuordnen kann. Welchen Herausforderungen Steuerermittler gegenüberstehen, wenn sie eine CD mit Steuerdaten zugespielt bekommen, konnten beispielsweise die Journalisten nachempfinden, die an der Aufdeckung der Paradise Papers beteiligt waren.
Bei der Sichtung der 13,4 Millionen Dokumente, die zunächst der Süddeutschen Zeitung zugespielt worden waren, stellte das International Consortium of Investigative Journalists schnell fest, dass die Daten aus den 21 Quellen nicht wirklich kompatibel waren. Erst in mehrmonatiger Kleinarbeit gelang es, die Informationen aus E-Mails, Scans und Datenbanken zu begradigen, sodass effektive Recherchen möglich waren.
So hatten die unterschiedlichen Quellen beispielsweise sehr unterschiedliche Standards bei der Erfassung von Namen und Adressen. Um Verbindungen zwischen Scheinfirmen und realen Personen aufzuzeigen, mussten die Journalisten daher sichergehen, dass sie die gleichen Namen in den unterschiedlichen Datenbanken tatsächlich korrekt zuordnen konnten. Das Ergebnis ist eine Datenbank, in der nun auch interessierte Bürger nach Verbindungen suchen können.
Solche grenzüberschreitenden Datenbanken sind auf staatlicher Seite eher die Ausnahme. So beklagte die EU-Kommission, dass pro Jahr in den Mitgliedsstaaten rund 50 Milliarden Euro Mehrwertsteuer veruntreut werden. Die Mittel der Betrüger sind dabei relativ einfach: Sie lügen dem Fiskus eines Landes vor, dass sie bereits in einem anderen Land Umsatzsteuer gezahlt haben. Solche Karussellgeschäfte sind lukrativ und bleiben dank der mangelnden Zusammenarbeit der Steuerbehörden lange unentdeckt.
Ende 2016 hat die EU-Kommission einen Aktionsplan vorgeschlagen, mit dem die Erhebung der Mehrwertsteuer in der Union endlich vereinheitlicht werden soll, damit solcher Betrug künftig ausgeschlossen wird. Wann der Aktionsplan jedoch tatsächlich umgesetzt werden wird, steht bisher noch in den Sternen. Und ohne eine gemeinsame Datenbank können auch die ausgefeiltesten Auswertungsmechanismen den Betrug nicht entdecken.

Kommentar schreiben